Unsupervised Memorability Modeling from Tip-of-the-Tongue Retrieval Queries
Modeling descriptive memorability signals without explicit human annotation
WACV 2026
Accepted at WACV 2026
Get in touch with us at behavior-in-the-wild@googlegroups.com
- ToT2MeM is the first large-scale unsupervised dataset for descriptive memorability, curated from tip-of-the-tongue retrieval threads on Reddit.
- ToT2MeM-Video pairs over 82,000 videos with open-ended recall descriptions, supporting rich multimodal modeling.
- ToT2MeM-Recall beats GPT-4o on open-ended memorability descriptions, and ToT2MeM-Retrieval delivers the first multimodal ToT retrieval system.
- All datasets, prompts, and models will be released for reproducible research.
Empirical Signals of What Sticks in Memory
These plots summarize how real recall attempts behave in tip-of-the-tongue forums. Instead of lab-based memory tasks, the signals come from natural search behavior in the wild.
The two groups below answer the following questions: Which kinds of content trigger more memory-search requests? Which kinds are solved quickly or slowly? And how does this behavior change with genre and time since release?
Popularity, Retrieval Friction, and Search Demand
This first set compares three signals: how popular content is outside Reddit, how often it is searched in ToT forums, and how long it takes before someone posts the right answer. A simple way to read these plots is to treat each point as one content item and look for broad trends instead of perfect lines.
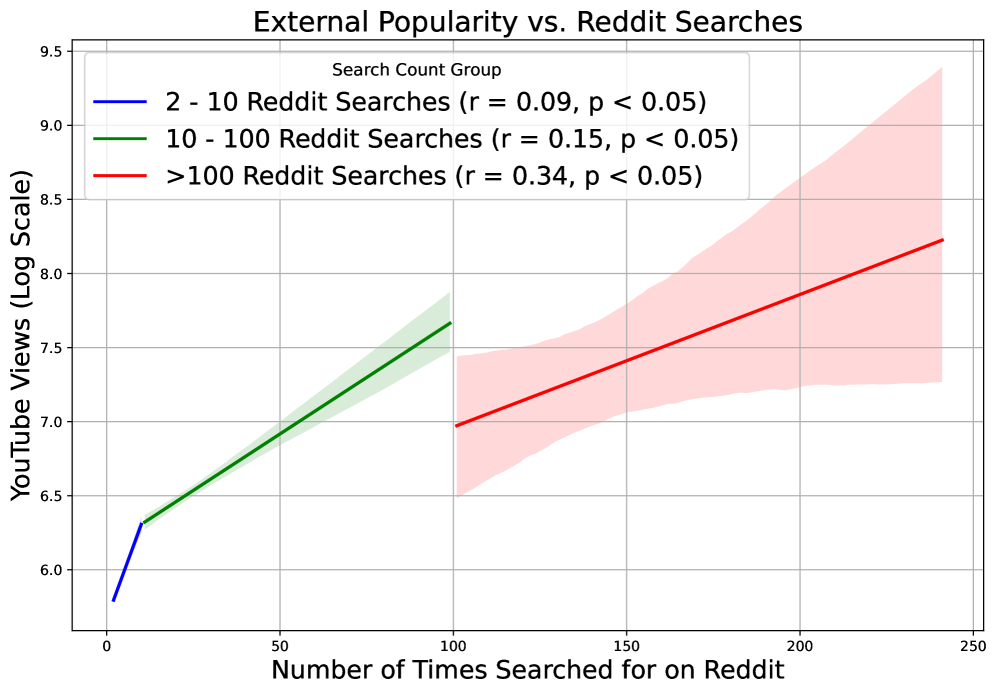
- In the popularity-versus-search plot, high-view items generate many more ToT queries, but there is still substantial spread at similar view counts, showing that visibility alone does not determine recall behavior. The strongest trend is in the high-search segment (r=0.34), where views rise from roughly 7.0 to 8.2 log-scale as search count moves from ~100 to ~240.
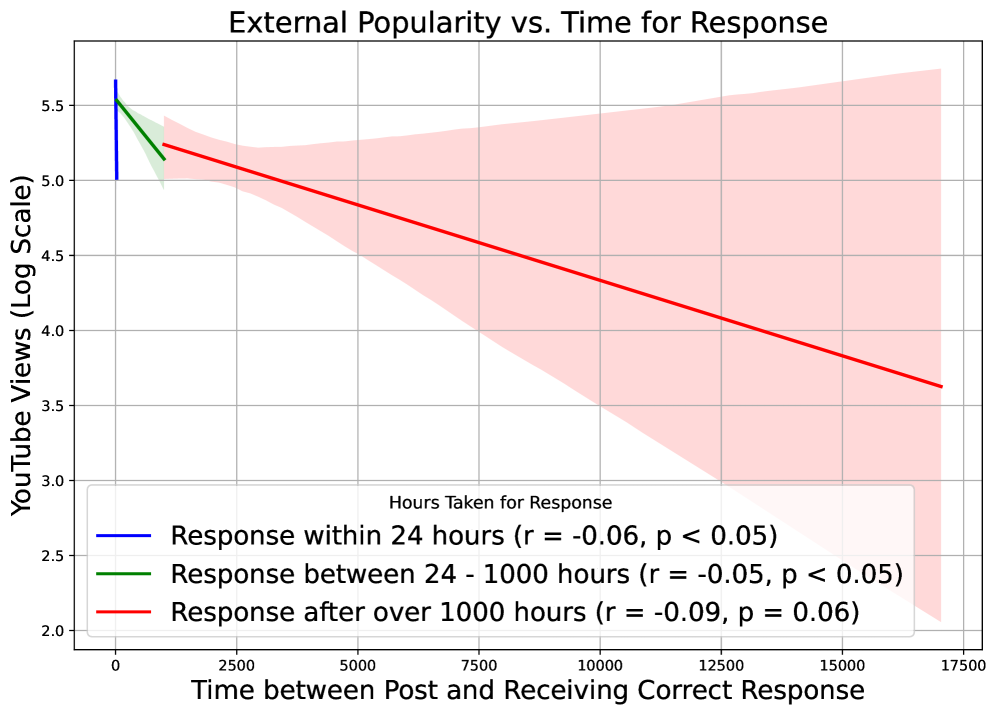
- In the popularity-versus-response-time plot, the trend is negative but weak: popular items are often solved faster, yet some still take long to resolve, indicating that ambiguous wording can offset familiarity. The >1000-hour curve drops by about 1.6 log units in views across the x-range, but confidence bands remain wide and correlations in the legend are small (r from -0.05 to -0.09).
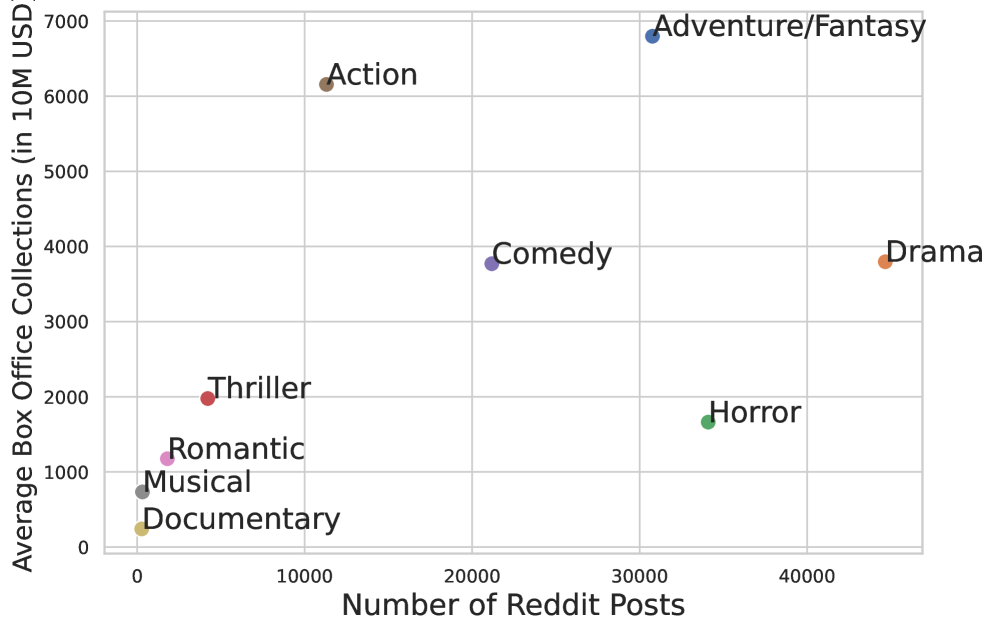
- In the genre-popularity-versus-search plot, genres with strong search demand are not always the ones with the highest box-office signal, suggesting that narrative distinctiveness can drive long-term recall demand. Drama (~45k posts) and Horror (~34k) are searched heavily despite lower box-office levels than Adventure/Fantasy and Action.
Together, these three plots suggest a two-step effect: broad exposure increases how often content enters memory search, while cue quality and genre characteristics determine how easily that memory can be resolved.
Temporal and Genre Dynamics of Memory Search
The second set focuses on time. One plot compares average solve time across genres. The other shows when people search relative to the original release date, which is useful for understanding long-term memory rather than short-term recognition.
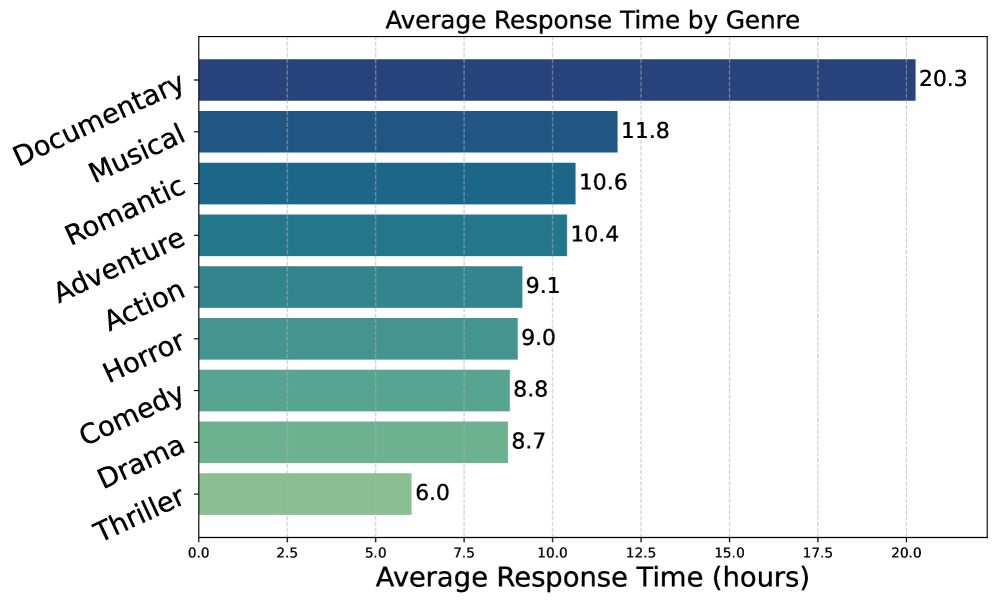
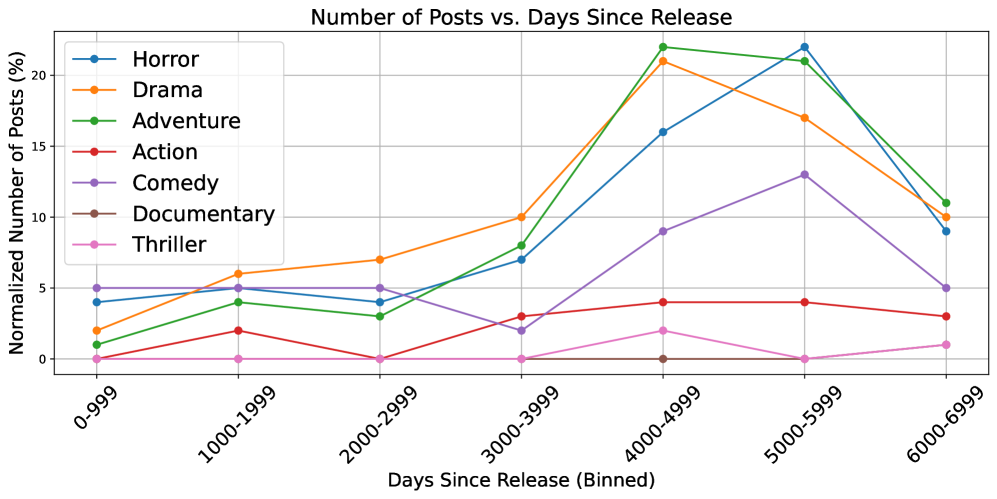
- In the genre-versus-average-response-time plot, the gap between fast and slow genres indicates that retrieval difficulty is not uniform across content categories. The span is large: 20.3h (Documentary) versus 6.0h (Thriller), a difference of 14.3 hours.
- In the time-since-release plot, many searches happen years after release, showing that unresolved memory traces remain active long after initial exposure. The highest points for major genres occur in 4000-5999 days, not in the earliest bins.
- Genre-specific temporal curves imply that some content types stay discoverable for longer periods, while others peak earlier, which matters for retrieval model evaluation over time. Documentary remains near zero across bins, while Adventure, Horror, and Drama exhibit strong late peaks between ~17% and ~22%.
These temporal observations reinforce that ToT2MeM captures realistic long-horizon retrieval conditions, not only immediate post-release recognition.
Abstract
Visual content memorability has intrigued the scientific community for decades, with applications ranging widely, from understanding nuanced aspects of human memory to enhancing content design. A significant challenge in progressing the field lies in the expensive process of collecting memorability annotations from humans. This limits the diversity and scalability of datasets for modeling visual content memorability. Most existing datasets are limited to collecting aggregate memorability scores for visual content, not capturing the nuanced memorability signals present in natural, open-ended recall descriptions. In this work, we introduce the first large-scale unsupervised dataset designed explicitly for modeling visual memorability signals, containing over 82,000 videos, accompanied by descriptive recall data. We leverage tip-of-the-tongue (ToT) retrieval queries from online platforms such as Reddit. We demonstrate that our unsupervised dataset provides rich signals for two memorability-related tasks: recall generation and ToT retrieval. Large vision-language models fine-tuned on our dataset outperform state-of-the-art models such as GPT-4o in generating open-ended memorability descriptions for visual content. We also employ a contrastive training strategy to create the first model capable of performing multimodal ToT retrieval. Our dataset and models present a novel direction, facilitating progress in visual content memorability research.
Why ToT2MeM?
- Covers 470K solved tip-of-the-tongue posts, guaranteeing high-quality descriptive recall signals without expensive human annotation campaigns.
- Includes 82K publicly available videos, each paired with structured scene crops, speech-to-text, and textual overlays for multimodal reasoning.
- Demonstrates strong alignment between recall descriptions and memorability outcomes, surfacing influential attributes such as genre, pacing, and emotional tonality.
- Enables two new tasks — Descriptive Recall Generation and Multimodal ToT Retrieval — with ready-to-use models (ToT2MeM-Recall and ToT2MeM-Retrieval).
Procedure Diagram
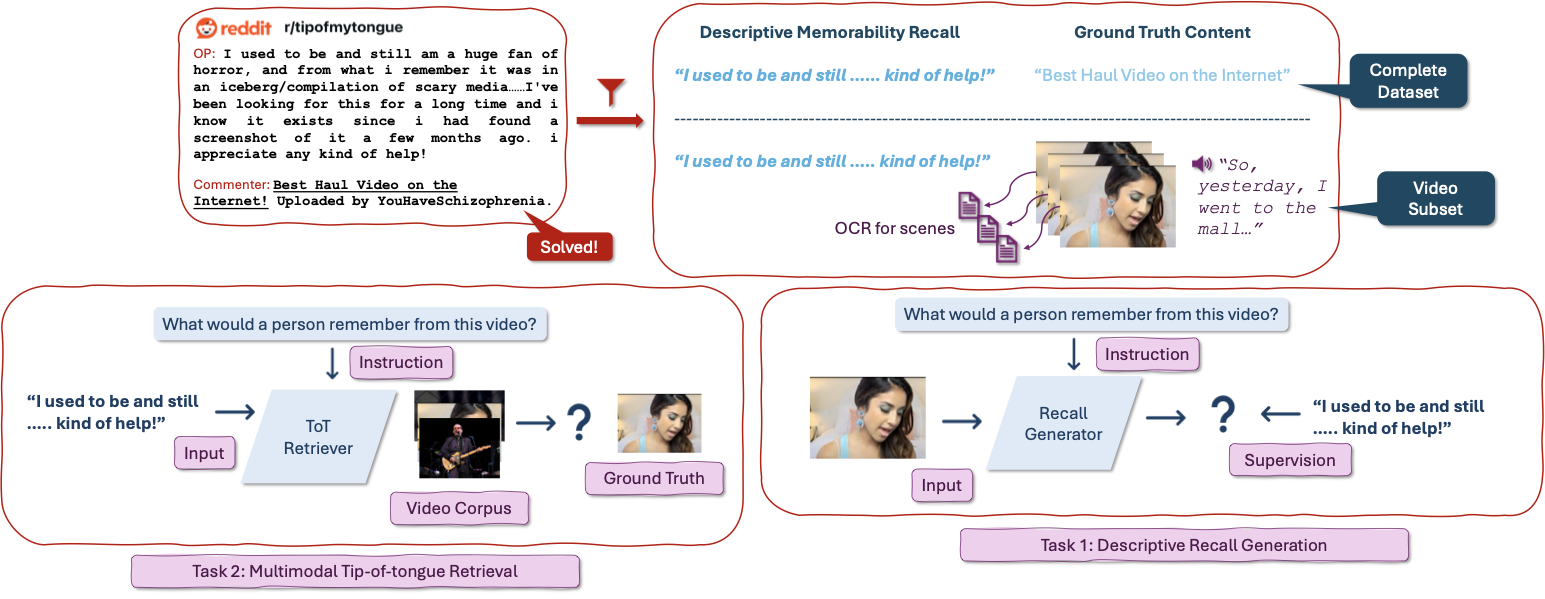
Dataset Snapshot
| Subset | What it contains | Scale |
|---|---|---|
| ToT2MeM | 470K solved Reddit posts linking vivid recall descriptions to the ground-truth media they were searching for. | 470,000 content-recall pairs |
| ToT2MeM-Video | Video subset with scene crops, audio transcripts, OCR, and metadata, filtered to clips shorter than 10 minutes. | 82,000 videos (with ~3.1M scene snippets) |
| External Factors | Emotion, genre, pacing, and popularity indicators derived from open data sources to study cross-factor memorability correlates. | 20+ high-level descriptors per content item |
Tasks Introduced
Descriptive Recall Generation
Train ToT2MeM-Recall to produce rich, human-like descriptions that capture what makes an item memorable. The model leverages vision-language cues, scene context, and ToT-style prompts to outperform GPT-4o in open-ended memorability narration.
Multimodal ToT Retrieval
Use contrastive training over recall descriptions and content embeddings to solve ToT-style search queries end-to-end. ToT2MeM-Retrieval is the first model to align descriptive cues with the exact video, audio, and textual evidence users recall.
Evaluation Highlights
- ToT2MeM-Recall surpasses GPT-4o and other large models on human evaluations for open-ended memorability descriptions, especially for niche content like archived commercials and episodic TV.
- Contrastive ToT2MeM-Retrieval delivers the first multimodal pipeline that can recover the right video purely from a free-form recall paragraph.
- Ablation studies show that scene-level OCR and ASR cues boost recall fidelity by more than 6% absolute over text-only variants.
- Qualitative analyses reveal that fast pacing, high emotional variance, and dialog-heavy soundtracks significantly impact long-term memorability.
Resources
The paper is available on arXiv. The ToT2MeM dataset (web-scale memorability) can be accessed on Hugging Face: behavior-in-the-wild/web_scale_memorability_all. Code, data loaders, and training utilities are maintained in the GitHub repository: behavior-in-the-wild/unsupervised-memorability. Reach out via behavior-in-the-wild@googlegroups.com for collaboration discussions.
BibTeX
@article{bhattacharyya2025unsupervised,
title={Unsupervised Memorability Modeling from Tip-of-the-Tongue Retrieval Queries},
author={Bhattacharyya, Sree and Singla, Yaman Kumar and Yarram, Sudhir and Singh, Somesh Kumar and Harini, S I and Wang, James Z},
journal={arXiv preprint arXiv:2511.20854},
year={2025}
}Terms Of Service
ToT2MeM data is collected from public Reddit communities and publicly available video links. We remove private or deleted media, NSFW tags, and bot-generated threads. The dataset does not expose usernames or personal identifiers. Please ensure your usage complies with the Reddit API terms and the licenses of the linked media. Access requires agreeing to our acceptable use policy that prohibits abusive, offensive, or discriminatory deployments.
Acknowledgement
We thank Adobe for sponsoring this research and the Reddit community for making the discussions publicly available. We also acknowledge the LLaMA and VLM ecosystems for releasing high-quality open models that accelerated our experimentation.